January 2003
How should yield
monitor data be combined with other information sources in choosing hybrids and
varieties?
J. Lowenberg-DeBoer
and Hernan Urcola
Introduction
Yield monitor data is widely acknowledged to be useful in choosing hybrids and varieties. Monitors make it easier to do on-farm testing under actual production conditions. But university extension specialists have cautioned producers not to focus exclusively on their on-farm data because that may not provide a good estimate of yield stability alone. They argue that producers should include data from university trials, seed industry demonstration plots and other sources in their decision-making.
“The primary benefits of widespread testing, multiple locations and years, are the increased ability to test under different weather patterns and to estimate stability of variety performance,” Robert Nielsen wrote in his chapter in Precision Farming Profitability.
Unfortunately, it is not always clear what the best way is to combine data from different sources in making hybrid and variety decisions. This article will summarize results on current farmer practices from a recent set of case studies at Purdue and it will outline an approach to using various data sources that comes from research in the Agricultural Economics Department.
Current Practices
Case studies of producer practices in hybrid and variety choices indicate that there is no standard way of combining information across sites. Most extension recommendations focus on how to evaluate yields from a given site or data source, and do not indicate how to combine data from different sources. Case studies in Indiana indicate that two common practices are:
1) Ranking hybrids or varieties at each site and then choosing those that rank high in multiple sites.
2) Giving absolute preference to on-farm data. If a hybrid or variety yields well on-farm then it is reordered. In this approach university trial and other data are useful mainly when on-farm genetic testing has not occurred.
There are many variations to ranking genetics at each site (1). Farmers agree that sites closer to the farming operation are more relevant, but they differ on which sites should be considered. They also differ on how much weight should be placed on data from any site. Should a ranking from a trial 100 miles away be given the same weight at a ranking in a strip trial on the farm?
It is rare for a hybrid or variety to rank near the top at all sites. How many top rankings are enough? How close to the top is high enough? Is a hybrid that had the top ranking out of 10 hybrids in a seed corn dealer’s plot comparable to a hybrid that was in the top 10 percent among 100 hybrids in a university trial?
In most cases producers focus on the yields from the last cropping season, but if testing over several weather patterns is important, then information from two, three or more years ago is potentially important. To the extent that producers focus on making decisions about new genetics, the question of using data from two or three years ago may be a moot point. For new genetics, there is often only one year of data.
The case studies indicate that giving absolute preference to on-farm data (2) is sometimes used to exclude a new hybrid or variety after the first year of production. Based on the recommendations of their seed dealer and/or results from university and other trials, some producers will plant small quantities of several promising hybrids and varieties. Any new genetics that do not out yield standard hybrids and varieties or have other problems (e.g. susceptible to plant diseases, lodging, high harvest losses) are not reordered. Basing a decision only on on-farm data may result in good genetics being dropped because of a rare event (e.g. abnormally cool spring, once in 20 year drought) and/or because of some on-farm error (e.g. planter setting mistake leads to low population or shallow planting depth). Also, giving absolute preference to on-farm data leaves question unanswered such as, how information from multiple sites is combined to choose new genetics.
Yield monitor data is not essential to implementing either of the ranking or absolute preference for on-farm data approaches. A yield monitor can make it easier for producers to collect on-farm data. Producers can use yield monitor data as soon as it is collected instead of wait for the posting to the website or publication.
Risk Management
From the perspective of a university agricultural economist, the hybrid and variety choice is a risk management problem. Each hybrid and variety has a certain distribution of potential yields and associated returns. No hybrid or variety is always best, so the problem is choosing the genetics that balance the quest for higher returns with acceptable levels of variability or risk. The right balance between expected return and risk will vary from person-to-person depending on their willingness to tolerate risk. One tool that agricultural economists sometimes use when they know something about the distributions, but do not know how individuals differ in terms of risk aversion is “stochastic dominance” (SD)
SD analysis is based on cumulative distributions. A cumulative distribution gives the chances that yields or returns will be below any given level. For example, in figure 1 the chance of Hybrid A having a return less than or equal to $75/acre is about 20%, while Hybrid B has a more than 60% chance of returning less than or equal to $75/acre.
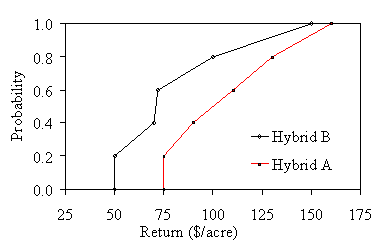
Figure 1. Example of First
Degree Stochastic Dominance (FDSD)
Cumulative distributions can be estimated from trial data, treating each “site-year” as one observation, ranking the observations from smallest to largest, assigning probabilities, and plotting them. In terms of Figure 1, each point in the figure represents one site-year of data. The most common approach is to assume all observations are equally likely, but it is possible to weight them differently.
The data used to estimate the distributions may come from several sources. For example for hybrid and variety choice could come from a combination of university trials, seed company plots and on-farm strip tests. Weighting information could be incorporated in the probabilities, which estimate the chance that the yield or return would occur in the producer’s operation. For instance, an observation from a university trial 100 miles away might be given half the weight of an on-farm yield observation.
SD analysis uses simple rules about risk preferences to categorize choices. In many cases SD analysis can be done visually. For example First Degree Stochastic Dominance (FDSD) describes a situation in which one distribution is always to the right of another distribution. The distribution on the right is preferred regardless of the individual’s risk attitude because it provides a higher outcome at all probability levels. In Figure 1, Hybrid A is preferred to Hybrid B because the A distribution has a higher return at any probability.
Second Degree Stochastic Dominance (SDSD) describes a situation in which the distributions cross, but one distribution always has less area under it. The area under a distribution can be seen as an indicator of the probability of a low outcome. In Figure 2, Hybrid A is preferred to Hybrid B because its distribution has less area under it at every return level and hence it is estimated as less likely to suffer from low returns. For SDSD to hold the area below one distribution must be larger than that of the other for every point and we can visually check key points. Below $75/acre, the Hybrid B distribution is to the left and the area under B exceeds that under A by the area h. Below $100/acre and h > i, the area under B is greater than the area under A. At $185/acre, areas h + j > I, so the area under A is smaller than the area under B.
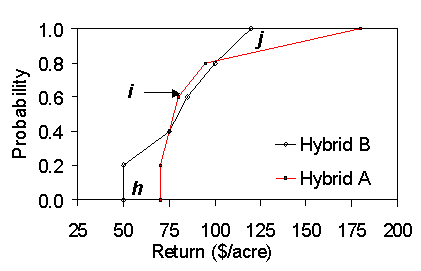
Figure 2. Example of Second Degree Stochastic Dominance (SDSD)
Some advantages of applying SD analysis to hybrid and variety choice when using yield monitor data:
A) It provides a standard way to make the comparison, so that all hybrids and varieties are evaluated the same way. This reduces the subjectivity of the decision.
B) SD is a way to summarize data from several sites and multiple years, without relying on one or two summary statistics (e.g. averages). With SD the effect of risk (e.g. a cool spring, a drought) can be incorporated into the decision-making.
C) Weighting can be incorporated into the probability estimate. Yields and returns from a distant site may be relevant, but less likely to occur than yields or returns from a nearby or on-farm trial.
D) It works whether or not yield monitor data is available for a certain type of seed. For instance, for new genetics the distributions might be estimated with only university and other off-farm trial data, while distributions for genetics already tested on the farm can include that information.
E) Observations from several years can be included in the distributions.
F) The idea of “transitivity” can be used to bridge the gap between genetics tested in one set of locations and those tested in other locations, if there are some genetics tested in both locations. For example, a seed choice would be considered “transitive” when Genetics "A" are preferred to "B" Genetics, and "B" Genetics are preferred to "C" Genetics, and resulting in "A" Genetics preferred to "C" Genetics.
Some disadvantages of SD for hybrid and variety choice:
A) When using the publicly available data, not all hybrids and varieties of interest are tested at all sites. The suggested method is to make SD comparisons with balanced data, that is information in which a hybrid or variety was grown at the same sites in the same years. This reduces the number of usable observations.
B) The SD analysis is pairwise by distribution, but graphically it does not always put observations from the same site-year at the same probability. For instance, in Figure I the two points at 20% probability are not necessarily the same genetics because data from each alternative is ranked separately.
C) Transitivity may not hold for genetics. Hybrid A may be preferred to Hybrid B in one location and not in another.
Conclusions
While it is important to use data from multiple sites in making hybrid and variety choices, the best way to combine information from several sources is not obvious. Recent case studies Purdue highlight the issues. Related research adds a potential analysis tool for combining yield or net return data from several sources, but sparseness of the data remains a problem. Many hybrid and variety trials are carried out each year, but none encompass the whole range of relevant seed products.
Some producers use the approach of ranking genetics within a site by yield or net return and selecting those that rank high at many sites. Unfortunately, this approach depends on the subjective weighting of the importance of each site and the arbitrary threshold of a “top ranking”. The absolute preference for on-farm data may lead to new hybrids and varieties being dropped because of rare events or operator error, and it leave open the question of how to deal with multiple sources of information for genetics that have never been tested on the farm.
SD analysis provides a standardized method for combining data from various sources, including on-farm yield monitor data, and weighting that data by relevance to the farming operation. It could work relatively well if all hybrids and varieties of interest were tested at the same sites, but it may run into trouble when some genetics are tested on a subset of sites, while others are tested elsewhere, with only a few hybrids and varieties tested on all sites. Research has used the assumption of transitivity to overcome this problem, but genetics by environmental interaction may mean that seed choices are not transitive.
For more information:
Urcola, Hernan, “Economic Value Added by Yield Monitor Data From the Producer’s Own Farm in Choosing Hybrids and Varieties,” M.S. Thesis, Department of Agricultural Economics, Purdue University, West Lafayette, IN, 2003.
Nielsen, Robert, “Opportunities for On-Farm Variety Performance Testing Using GPS Enabled Technologies”, in J. Lowenberg-DeBoer and K. Erickson, Eds, Precision Farming Profitability, Purdue University, Agricultural Research Program, 2000, p. 12-18.